AstronomyCalc tutorial¶
This is a tutorial to show an usage of the AstronomyCalc package. Corresponding notebooks can be found here.
[1]:
import numpy as np
import matplotlib.pyplot as plt
from astropy import units
[2]:
try:
import AstronomyCalc
except:
!pip install git+https://github.com/sambit-giri/AstronomyCalc.git
import AstronomyCalc
from AstronomyCalc import create_data
Model universes¶
Here simulation of a few model universes are shown.
[3]:
code_param_dict = {'zmin': 0.01, 'zmax': 11.0, 'Nz': 100, 'verbose': True}
Einsten-de Sitter universe¶
In this model, the universe is assumed to be dominated by matter.
[4]:
cosmo_dict = {'Om': 1.0, 'Or': 0, 'Ok': 0, 'Ode': 0, 'h': 0.68}
param_EdS = AstronomyCalc.param(cosmo=cosmo_dict, code=code_param_dict)
AstronomyCalc.plot_universe_pie(cosmo_dict, title="Content of Einsten-de Sitter universe")
[5]:
D_EdS = AstronomyCalc.CosmoDistances(param_EdS)
de Sitter universe¶
In this model, the universe is assumed to be dominated by dark energy.
[6]:
cosmo_dict = {'Om': 0.0, 'Or': 0, 'Ok': 0, 'Ode': 1.0, 'h': 0.68}
param_dS = AstronomyCalc.param(cosmo=cosmo_dict, code=code_param_dict)
AstronomyCalc.plot_universe_pie(cosmo_dict, title="Content of de Sitter universe")
[7]:
D_dS = AstronomyCalc.CosmoDistances(param_dS)
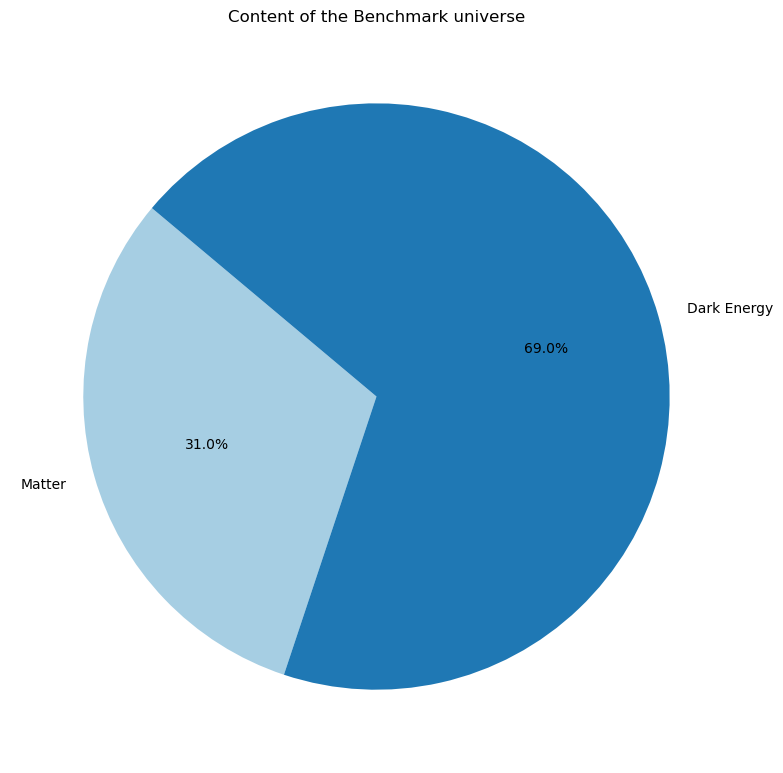
Benchmark model or flat \(\Lambda\)-cold dark matter (\(\Lambda\)CDM) universe¶
In this model, the universe is flat (\(\Omega_m+\Omega_r+\Omega_{DE}=1\) or \(\Omega_\kappa=0\)) universe containing cold dark matter and constant dark energy. This model best explains the Cosmic Microwave Background (CMB) observations from WMAP and Planck.
[8]:
cosmo_dict = {'Om': 0.31, 'Or': 0.0, 'Ok': 0.0, 'Ode': 0.69, 'h': 0.68}
param = AstronomyCalc.param(cosmo=cosmo_dict, code=code_param_dict)
AstronomyCalc.plot_universe_pie(cosmo_dict, title="Content of the Benchmark universe")
[9]:
D = AstronomyCalc.CosmoDistances(param)
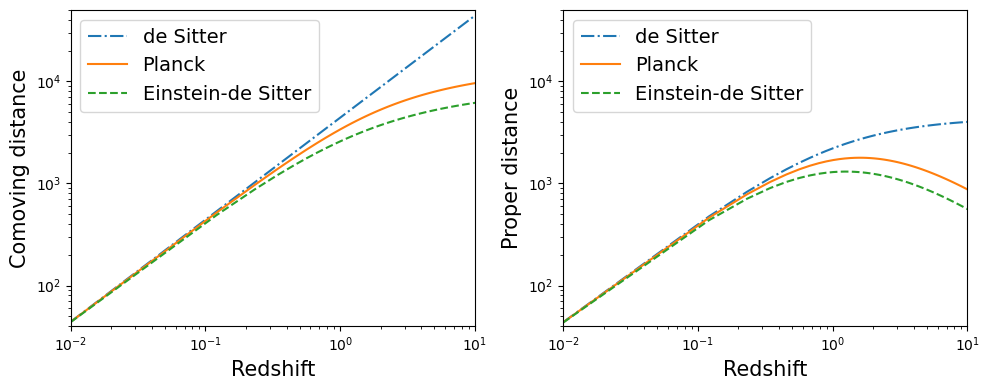
Plot distances in model universes¶
[10]:
zs = np.linspace(param.code.zmin,param.code.zmax,param.code.Nz)
fig, axs = plt.subplots(1,2,figsize=(10,4))
axs[0].loglog(zs, D_dS.comoving_dist(zs), ls='-.', label='de Sitter')
axs[0].loglog(zs, D.comoving_dist(zs), ls='-', label='Planck')
axs[0].loglog(zs, D_EdS.comoving_dist(zs), ls='--', label='Einstein-de Sitter')
axs[0].legend(loc=2, fontsize=14)
axs[0].set_xlabel('Redshift', fontsize=15)
axs[0].set_ylabel('Comoving distance', fontsize=15)
axs[0].axis([0.01,10,40,5e4])
axs[1].loglog(zs, D_dS.proper_dist(zs), ls='-.', label='de Sitter')
axs[1].loglog(zs, D.proper_dist(zs), ls='-', label='Planck')
axs[1].loglog(zs, D_EdS.proper_dist(zs), ls='--', label='Einstein-de Sitter')
axs[1].legend(loc=2, fontsize=14)
axs[1].set_xlabel('Redshift', fontsize=15)
axs[1].set_ylabel('Proper distance', fontsize=15)
axs[1].axis([0.01,10,40,5e4])
plt.tight_layout()
plt.show()
Hubble diagram¶
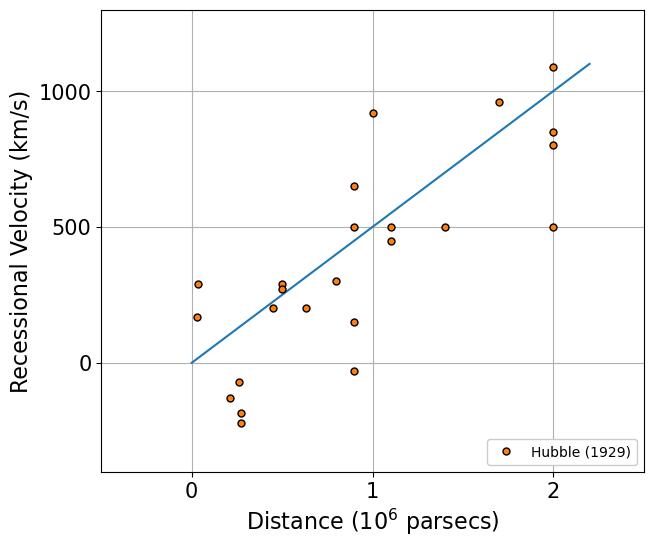
Original data used in Hubble (1929)¶
Edwin Hubble measured the recession velocity (\(v\)) of the galaxies at different distances (\(d\)). To explain this data, he fitted a line \(v=H_0 d\), where \(H_0\) is a constant. This constant tells us how fast objects are moving away from us, which is a fundamental aspect of cosmology.
[11]:
dist_Hubble1929, vel_Hubble1929 = create_data.Hubble1929_data()
[12]:
v_func = lambda r,H0: H0*r
rr = np.linspace(0,2.2)
fig, ax = plt.subplots(1,1,figsize=(7,6))
ax.errorbar(dist_Hubble1929, vel_Hubble1929,
ls=' ',
color='C1',
marker='o', markeredgecolor='k', markersize=5,
label='Hubble (1929)', zorder=5)
ax.plot(rr, v_func(rr,500), c='C0') # 500 km/s/Mpc is the value of Hubble constant estimated in Hubble (1929).
ax.legend(loc=4, facecolor='white', framealpha=1)
ax.set_xlabel(r'Distance ($10^6$ parsecs)', fontsize=16)
ax.set_ylabel(r'Recessional Velocity (km/s)', fontsize=16)
ax.set_xticks([0,1,2])
ax.set_yticks([0,500,1000])
ax.axis([-0.5,2.5,-400,1300])
ax.tick_params(axis='both', which='major', labelsize=15)
ax.grid()
plt.show()
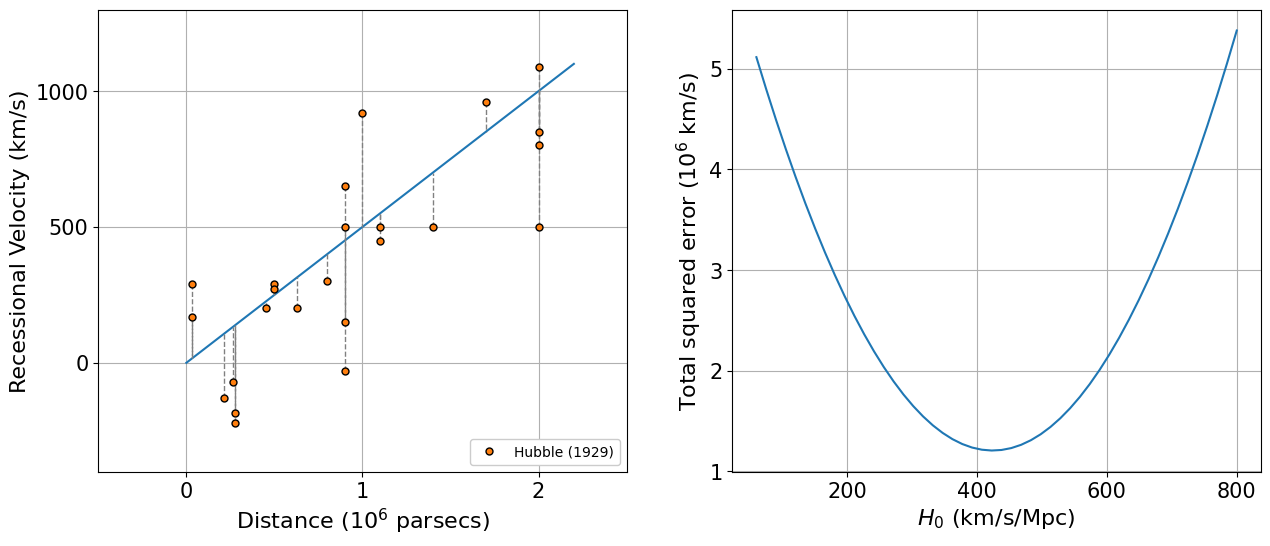
Least Square Fit¶
To find the best fit model, we require a loss or cost function that describes how far the model is from the data. For the above data, we can find the best fit model by minimising the total squared error between the model and the observed data, which can be give as,
\(r^2 = \sum_i \left[y_i-f(x_i|\theta)\right]^2\),
where \((x_i,y_i)\) are the data and \(\theta\) represents the model parameters.
[13]:
least_sq = lambda y,f: np.vectorize(lambda f: np.sum((y-f)**2))
[14]:
v_func = lambda r,H0: H0*r
rr = np.linspace(0,2.2)
fig, axs = plt.subplots(1,2,figsize=(15,6))
ax = axs[0]
ax.errorbar(dist_Hubble1929, vel_Hubble1929,
ls=' ',
color='C1',
marker='o', markeredgecolor='k', markersize=5,
label='Hubble (1929)', zorder=5)
ax.plot(rr, v_func(rr,500), c='C0') # 500 km/s/Mpc is the value of Hubble constant estimated in Hubble (1929).
# Plot vertical lines from every data point to the line
for dist, vel in zip(dist_Hubble1929, vel_Hubble1929):
ax.plot([dist, dist], [vel, v_func(dist, 500)], c='gray', linestyle='--', linewidth=1)
ax.legend(loc=4, facecolor='white', framealpha=1)
ax.set_xlabel(r'Distance ($10^6$ parsecs)', fontsize=16)
ax.set_ylabel(r'Recessional Velocity (km/s)', fontsize=16)
ax.set_xticks([0,1,2])
ax.set_yticks([0,500,1000])
ax.axis([-0.5,2.5,-400,1300])
ax.tick_params(axis='both', which='major', labelsize=15)
ax.grid()
least_sq = lambda y,f: np.sum((y-f)**2)
H0_array = np.linspace(60,800)
least_sq_array = np.array([least_sq(vel_Hubble1929,v_func(dist_Hubble1929,Hi)) for Hi in H0_array])
ax = axs[1]
ax.plot(H0_array, least_sq_array/1e6, c='C0')
# ax.legend(loc=4, facecolor='white', framealpha=1)
ax.set_xlabel(r'$H_0$ (km/s/Mpc)', fontsize=16)
ax.set_ylabel(r'Total squared error ($10^6$ km/s)', fontsize=16)
ax.tick_params(axis='both', which='major', labelsize=15)
ax.grid()
plt.show()
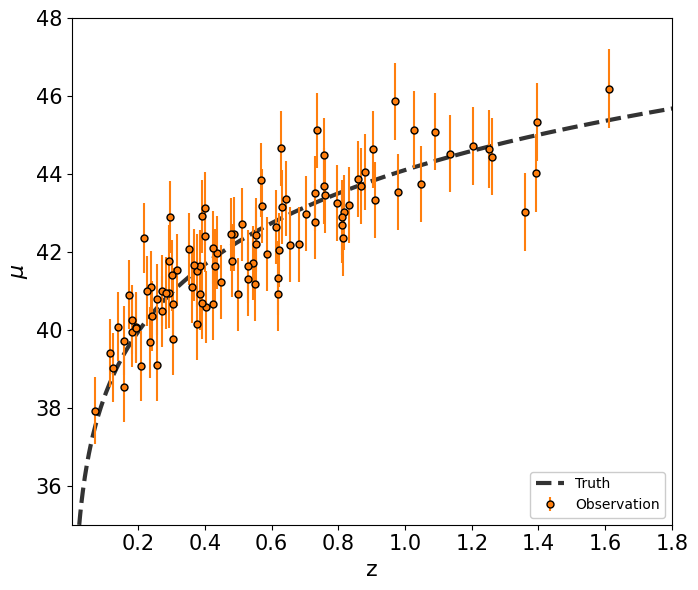
Generate synthetic supernova data¶
We generate distance modulus data \(\mu(z)\) given as,
\(\mu(z) = 5\log_{10}\left(\frac{d_L(z)}{1~\mathrm{Mpc}}\right)+25\) ,
where \(d_L\) is the luminosity distance estimated by observing supernova. This distance is related to the comoving distance \(d_c(z)\) as,
\(d_L(z) = (1+z) d_c(z) = (1+z)\frac{c}{H_0}\int\frac{dz}{\left[\Omega_m(1+z)^3+\Omega_\Lambda\right]^{1/2}}\) .
[15]:
code_param_dict = {'zmin': 0.001, 'zmax': 3.0, 'Nz': 100, 'verbose': True}
cosmo_dict = {'Om': 0.30, 'Or': 0, 'Ok': 0, 'Ode': 0.70, 'h': 0.70}
param = AstronomyCalc.param(cosmo=cosmo_dict, code=code_param_dict)
print('Cosmological parameters')
print(param.cosmo.__dict__)
print('Code parameters')
print(param.code.__dict__)
Cosmological parameters
{'Om': 0.3, 'Or': 0, 'Ok': 0, 'Ode': 0.7, 'h': 0.7, 'Tcmb': 2.725}
Code parameters
{'zmin': 0.001, 'zmax': 3.0, 'Nz': 100, 'verbose': True}
[16]:
z_true = np.linspace(0.01, 2, 1000)
mu_true = AstronomyCalc.distance_modulus(param, z=z_true)
z_sample, mu_sample, dmu = create_data.generate_distance_modulus()
print(z_sample.shape, mu_sample.shape, dmu.shape)
(100,) (100,) (100,)
[17]:
fig, ax = plt.subplots(1,1,figsize=(7,6))
ax.errorbar(z_sample, mu_sample, yerr=dmu,
ls=' ',
color='C1',
marker='o', markeredgecolor='k', markersize=5,
label='Observation', zorder=5)
ax.plot(z_true, mu_true, c='k', alpha=0.8, lw=3, ls='--', label='Truth')
ax.legend(loc=4, facecolor='white', framealpha=1)
ax.set_xlabel(r'z', fontsize=16)
ax.set_ylabel(r'$\mu$', fontsize=16)
ax.axis([0.001,1.8,35,48])
ax.tick_params(axis='both', which='major', labelsize=15)
plt.tight_layout()
plt.show()
Posterior distribution¶
To find a model for a dataset with errorbar, we can define the loss function using the posterior distribution defined by the Bayes’ theorem as,
\(p(\theta|{x_i,y_i})\propto p({x_i,y_i}|\theta) p(\theta)\) ,
where \(p({x_i,y_i}|\theta)\) and \(p(\theta)\) are the data likelihood and the prior distribution, respectively.
Based on the central limit theorem, the each supernova data point can be assumed to be well defined by Gaussian distribution and, therefore, the likelihood can be given as,
\(p({x_i,y_i}|\theta) = \frac{1}{\sqrt{2\pi\sigma^2_i}} \mathrm{exp}\left(-\frac{[y_i-f(x_i|\theta)]^2}{2\sigma^2_i}\right)\) ,
where \(\sigma_i\) is the standard deviation of the \(i^\mathrm{th}\) data point. If we assume no prior knowledge, then \(p(\theta)=1\). Instead of likelihood (\(L\)), it is more convenient to work with log-likelihood:
\(\log(L) \propto - \sum^N_i \left(\frac{[y_i-f(x_i|\theta)]^2}{2\sigma^2_i}\right)\),
which should maximize for the best-fit. Therefore the loss function should be:
\(_{~~\theta}^\mathrm{min}\sum^N_i \left(\frac{[y_i-f(x_i|\theta)]^2}{2\sigma^2_i}\right)\)
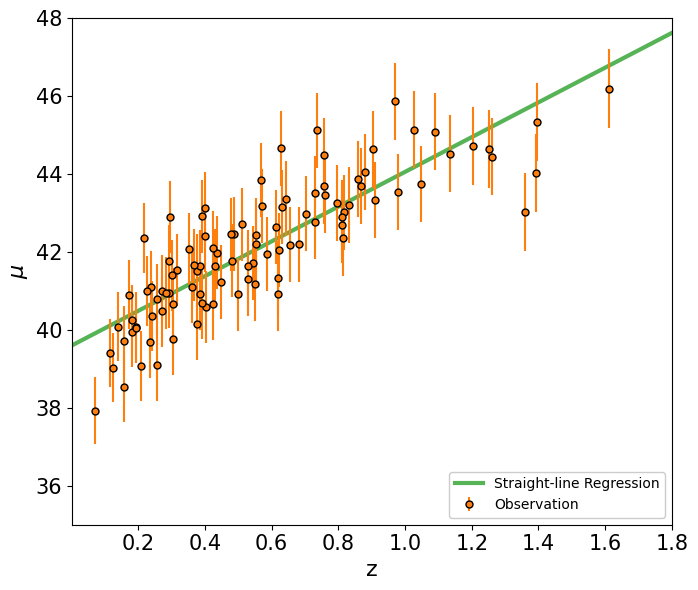
Linear Regression¶
This regression finds a parametric model where \(f(x|\theta)=\sum^k_p\theta_p g_p(x)\), where the functions \(g_p(x)\) can be nonlinear functions of x.
For a straight-line, \(f(x|\theta)=\theta_0 + \theta_1 x\).
[18]:
from astroML.linear_model import LinearRegression
/Users/sambit/miniconda3/envs/py3/lib/python3.10/site-packages/astroML/linear_model/linear_regression_errors.py:10: UserWarning: LinearRegressionwithErrors requires PyMC3 to be installed
warnings.warn('LinearRegressionwithErrors requires PyMC3 to be installed')
[19]:
model = LinearRegression()
model.fit(z_sample[:,None], mu_sample, dmu)
zz = np.linspace(0,2)
mu_line = model.predict(zz[:,None])
print(mu_line.shape)
(50,)
[20]:
fig, ax = plt.subplots(1,1,figsize=(7,6))
ax.errorbar(z_sample, mu_sample, yerr=dmu,
ls=' ',
color='C1',
marker='o', markeredgecolor='k', markersize=5,
label='Observation', zorder=5)
ax.plot(zz, mu_line, c='C2', alpha=0.8, lw=3, label='Straight-line Regression')
ax.legend(loc=4, facecolor='white', framealpha=1)
ax.set_xlabel(r'z', fontsize=16)
ax.set_ylabel(r'$\mu$', fontsize=16)
ax.axis([0.001,1.8,35,48])
ax.tick_params(axis='both', which='major', labelsize=15)
plt.tight_layout()
plt.show()
Polynomial Regression¶
This is also a linear regression, but higher order dependence on the independent variable is explored, which means \(g_p(x)\) is could be higher order polynomial.
[21]:
from astroML.linear_model import PolynomialRegression
For a third-order polynomial, \(f(x|\theta)=\theta_0 + \theta_1 x + \theta_2 x^2 + \theta_3 x^3\).
[22]:
model = PolynomialRegression(degree=3)
model.fit(z_sample[:,None], mu_sample, dmu)
zz = np.linspace(0,2)
mu_poly3 = model.predict(zz[:,None])
print(mu_poly3.shape)
(50,)
For a fifth-order polynomial, \(f(x|\theta)=\theta_0 + \theta_1 x + \theta_2 x^2 + \theta_3 x^3 + \theta_4 x^4 + \theta_5 x^5\).
[23]:
model = PolynomialRegression(degree=5)
model.fit(z_sample[:,None], mu_sample, dmu)
zz = np.linspace(0,2)
mu_poly5 = model.predict(zz[:,None])
print(mu_poly5.shape)
(50,)
[24]:
fig, ax = plt.subplots(1,1,figsize=(7,6))
ax.errorbar(z_sample, mu_sample, yerr=dmu,
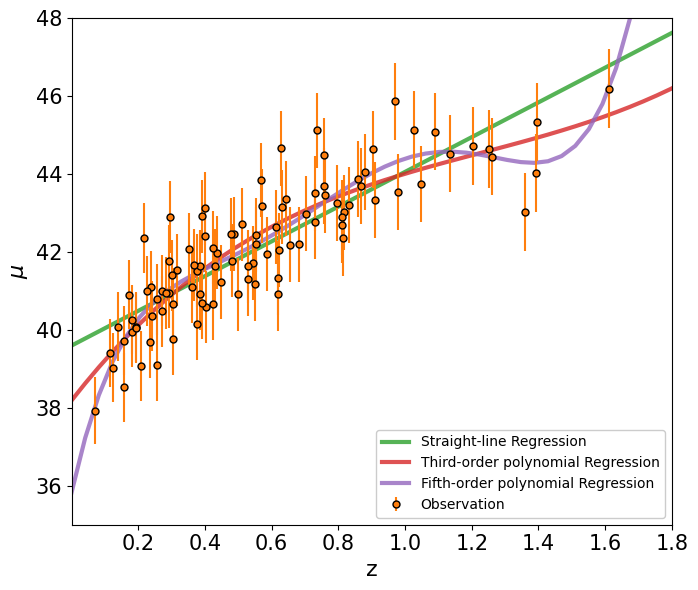
ls=' ',
color='C1',
marker='o', markeredgecolor='k', markersize=5,
label='Observation', zorder=5)
ax.plot(zz, mu_line, c='C2', alpha=0.8, lw=3, label='Straight-line Regression')
ax.plot(zz, mu_poly3, c='C3', alpha=0.8, lw=3, label='Third-order polynomial Regression')
ax.plot(zz, mu_poly5, c='C4', alpha=0.8, lw=3, label='Fifth-order polynomial Regression')
ax.legend(loc=4, facecolor='white', framealpha=1)
ax.set_xlabel(r'z', fontsize=16)
ax.set_ylabel(r'$\mu$', fontsize=16)
ax.axis([0.001,1.8,35,48])
ax.tick_params(axis='both', which='major', labelsize=15)
plt.tight_layout()
plt.show()
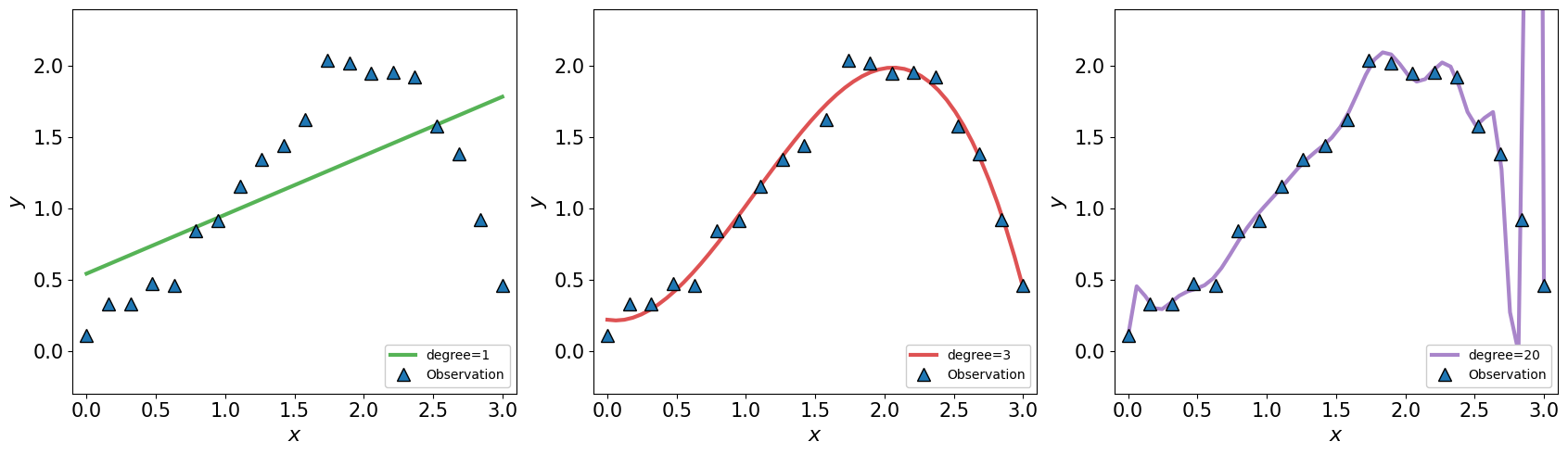
Underfitting vs overfitting¶
To illustrate this effect, we consider a simple example \(y=x \sin(x)\) with some scatter.
[25]:
x_simple = np.linspace(0,3,20)
yerr_simple = 0.01*np.ones_like(x_simple)
y_simple = 0.2+x_simple*np.sin(x_simple)+0.1*np.random.randn(len(x_simple))
[26]:
fig, axs = plt.subplots(1,3,figsize=(17,5))
for i,deg in enumerate([1,3,20]):
ax = axs[i]
model = PolynomialRegression(degree=deg)
model.fit(x_simple[:,None], y_simple, yerr_simple)
xx = np.linspace(0,3)
yy = model.predict(xx[:,None])
ax.errorbar(x_simple, y_simple,
ls=' ',
color='C0',
marker='^', markeredgecolor='k', markersize=10,
label='Observation', zorder=5)
ax.plot(xx, yy, c=f'C{i+2}', lw=3, alpha=0.8, label=f'degree={deg}')
ax.legend(loc=4, facecolor='white', framealpha=1)
ax.set_xlabel(r'$x$', fontsize=16)
ax.set_ylabel(r'$y$', fontsize=16)
ax.axis([-0.1,3.1,-0.3,2.4])
ax.tick_params(axis='both', which='major', labelsize=15)
plt.tight_layout()
plt.show()
Cross-Validation¶
We divide the data into three sets: training, validation and testing set. In this method, the model is fit on the training set and validated using the validation set for different complexity of the model.
[27]:
from sklearn.model_selection import train_test_split
X, y = x_simple.copy(), y_simple.copy()
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=1)
X_test, X_val, y_test, y_val = train_test_split(X_test, y_test, test_size=0.5, random_state=1)
yerr_train, yerr_val, yerr_test = yerr_simple[:len(y_train)], yerr_simple[:len(y_val)], yerr_simple[:len(y_test)]
print('Full data:', X.shape, y.shape)
print('Training data:', X_train.shape, y_train.shape)
print('Validation data:', X_val.shape, y_val.shape)
print('Testing data:', X_test.shape, y_test.shape)
Full data: (20,) (20,)
Training data: (14,) (14,)
Validation data: (3,) (3,)
Testing data: (3,) (3,)
We can define the “Goodness of fit” using mean squared error (MSE):
\(\mathrm{MSE} = \frac{1}{N}\sum^N_i \left[y_i-f(x_i|\theta)\right]^2\)
[28]:
from sklearn.metrics import mean_squared_error
[29]:
degree_list = np.arange(15)
mse_train = np.zeros_like(degree_list, dtype=float)
mse_val = np.zeros_like(degree_list, dtype=float)
for i,deg in enumerate(degree_list):
model = PolynomialRegression(degree=deg)
model.fit(X_train[:,None], y_train, yerr_train)
y_pred = model.predict(X_val[:,None])
mse_val[i] = mean_squared_error(y_val,y_pred)
y_pred = model.predict(X_train[:,None])
mse_train[i] = mean_squared_error(y_train,y_pred)
[30]:
fig, ax = plt.subplots(1,1,figsize=(7,6))
ax.plot(degree_list, mse_train, c='k', alpha=0.8, lw=3, ls='-', label='Training')
ax.plot(degree_list, mse_val, c='k', alpha=0.8, lw=3, ls='--', label='Validation')
ax.legend(loc=2, facecolor='white', framealpha=1)
ax.set_xlabel(r'Polynomial degree', fontsize=16)
ax.set_ylabel(r'Mean Squared Error (MSE)', fontsize=16)
ax.axis([-0.1,14,-0.1,0.9])
ax.tick_params(axis='both', which='major', labelsize=15)
plt.tight_layout()
plt.show()
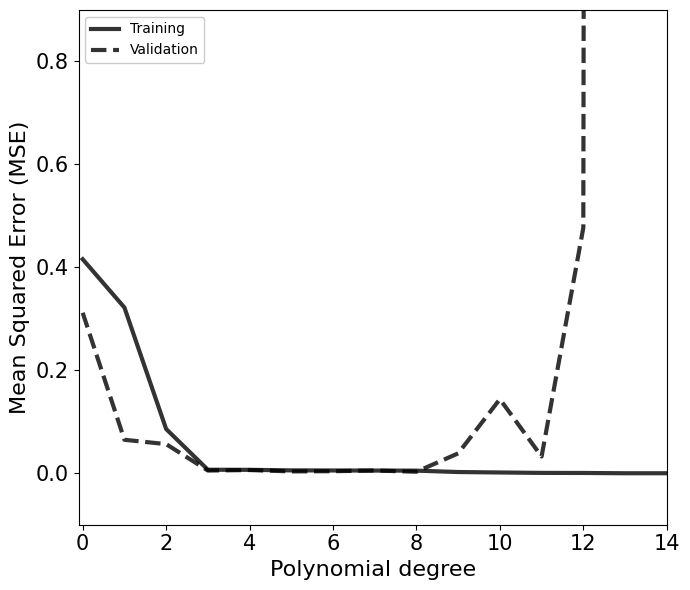
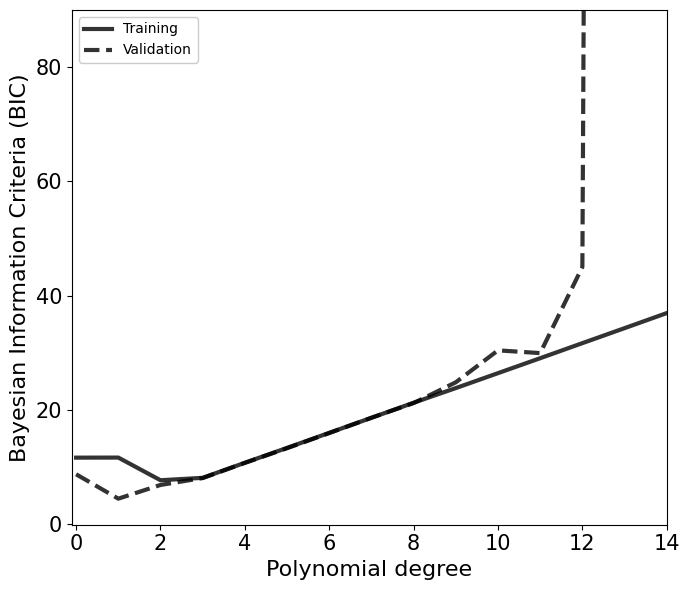
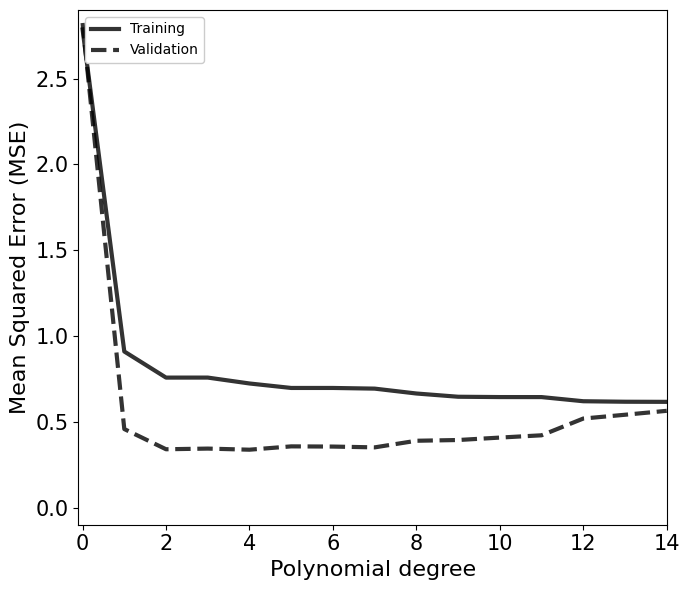
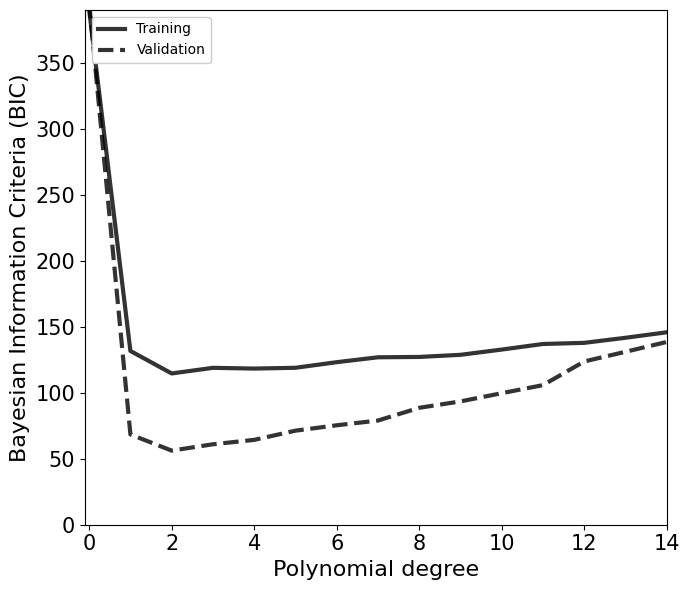
Multiple options for the degree of the polynomial is possible based on the above plot. Based on the Occam’s razor, the simplest models among them should be choosen.
A general metric to test this criteria is Bayesian Information Criteria (BIC) defined as,
\(\mathrm{BIC} = k\log(N)-2\log(L_\mathrm{max})\) ,
where \(k\) and \(N\) are the number of degrees of freedom and data points, respectively. \(L_\mathrm{max}\) is the maximum likelihood values from the training process.
[31]:
def BIC(model, X_train, y_train, N):
k = model.degree
y_pred = model.predict(X_train[:,None])
Lmax = np.exp(- mean_squared_error(y_train,y_pred)*N)
# print(N, k*np.log(N),Lmax)
bic = k*np.log(N)-2*np.log(Lmax)
return bic
[32]:
degree_list = np.arange(15)
bic_train = np.zeros_like(degree_list, dtype=float)
bic_val = np.zeros_like(degree_list, dtype=float)
for i,deg in enumerate(degree_list):
model = PolynomialRegression(degree=deg)
model.fit(X_train[:,None], y_train, yerr_train)
y_pred = model.predict(X_val[:,None])
bic_val[i] = BIC(model,X_val,y_val,X_train.shape[0])
y_pred = model.predict(X_train[:,None])
bic_train[i] = BIC(model,X_train,y_train,X_train.shape[0])
[33]:
fig, ax = plt.subplots(1,1,figsize=(7,6))
ax.plot(degree_list, bic_train, c='k', alpha=0.8, lw=3, ls='-', label='Training')
ax.plot(degree_list, bic_val, c='k', alpha=0.8, lw=3, ls='--', label='Validation')
ax.legend(loc=2, facecolor='white', framealpha=1)
ax.set_xlabel(r'Polynomial degree', fontsize=16)
ax.set_ylabel(r'Bayesian Information Criteria (BIC)', fontsize=16)
ax.axis([-0.1,14,-0.1,90])
ax.tick_params(axis='both', which='major', labelsize=15)
plt.tight_layout()
plt.show()
Polynomial Regression of Supernova data¶
[34]:
from sklearn.model_selection import train_test_split
X, y = z_sample.copy(), np.vstack((mu_sample,dmu)).T.copy()
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=1)
X_test, X_val, y_test, y_val = train_test_split(X_test, y_test, test_size=0.5, random_state=1)
y_train, yerr_train = y_train[:,0], y_train[:,1]
y_test, yerr_test = y_test[:,0], y_test[:,1]
y_val, yerr_val = y_val[:,0], y_val[:,1]
print('Full data:', X.shape, y.shape)
print('Training data:', X_train.shape, y_train.shape, yerr_train.shape)
print('Validation data:', X_val.shape, y_val.shape, yerr_val.shape)
print('Testing data:', X_test.shape, y_test.shape, yerr_test.shape)
Full data: (100,) (100, 2)
Training data: (70,) (70,) (70,)
Validation data: (15,) (15,) (15,)
Testing data: (15,) (15,) (15,)
[35]:
degree_list = np.arange(15)
mse_train = np.zeros_like(degree_list, dtype=float)
mse_val = np.zeros_like(degree_list, dtype=float)
for i,deg in enumerate(degree_list):
model = PolynomialRegression(degree=deg)
model.fit(X_train[:,None], y_train, yerr_train)
y_pred = model.predict(X_val[:,None])
mse_val[i] = mean_squared_error(y_val,y_pred)
y_pred = model.predict(X_train[:,None])
mse_train[i] = mean_squared_error(y_train,y_pred)
[36]:
fig, ax = plt.subplots(1,1,figsize=(7,6))
ax.plot(degree_list, mse_train, c='k', alpha=0.8, lw=3, ls='-', label='Training')
ax.plot(degree_list, mse_val, c='k', alpha=0.8, lw=3, ls='--', label='Validation')
ax.legend(loc=2, facecolor='white', framealpha=1)
ax.set_xlabel(r'Polynomial degree', fontsize=16)
ax.set_ylabel(r'Mean Squared Error (MSE)', fontsize=16)
ax.axis([-0.1,14,-0.1,2.9])
ax.tick_params(axis='both', which='major', labelsize=15)
plt.tight_layout()
plt.show()
[37]:
degree_list = np.arange(15)
bic_train = np.zeros_like(degree_list, dtype=float)
bic_val = np.zeros_like(degree_list, dtype=float)
for i,deg in enumerate(degree_list):
model = PolynomialRegression(degree=deg)
model.fit(X_train[:,None], y_train, yerr_train)
y_pred = model.predict(X_val[:,None])
bic_val[i] = BIC(model,X_val,y_val,X_train.shape[0])
y_pred = model.predict(X_train[:,None])
bic_train[i] = BIC(model,X_train,y_train,X_train.shape[0])
[38]:
fig, ax = plt.subplots(1,1,figsize=(7,6))
ax.plot(degree_list, bic_train, c='k', alpha=0.8, lw=3, ls='-', label='Training')
ax.plot(degree_list, bic_val, c='k', alpha=0.8, lw=3, ls='--', label='Validation')
ax.legend(loc=2, facecolor='white', framealpha=1)
ax.set_xlabel(r'Polynomial degree', fontsize=16)
ax.set_ylabel(r'Bayesian Information Criteria (BIC)', fontsize=16)
ax.axis([-0.1,14,-0.1,390])
ax.tick_params(axis='both', which='major', labelsize=15)
plt.tight_layout()
plt.show()
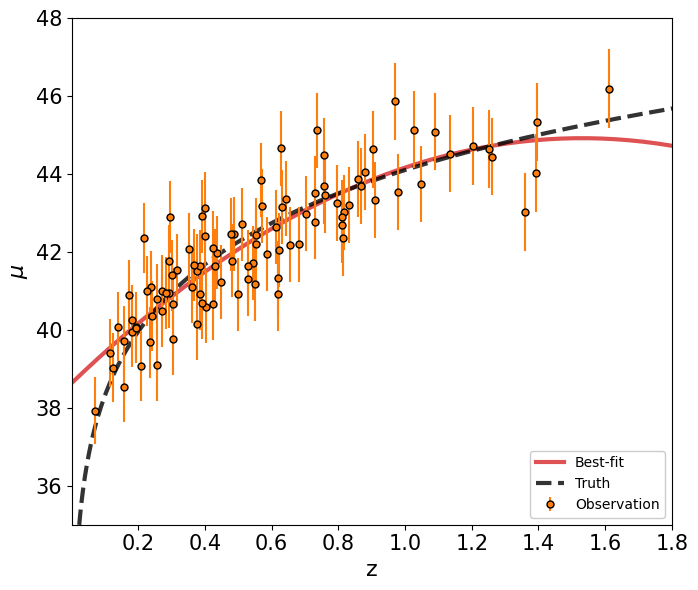
[39]:
model = PolynomialRegression(degree=2)
model.fit(z_sample[:,None], mu_sample, dmu)
zz = np.linspace(0,2)
mu_poly = model.predict(zz[:,None])
print(mu_poly.shape)
(50,)
[40]:
fig, ax = plt.subplots(1,1,figsize=(7,6))
ax.errorbar(z_sample, mu_sample, yerr=dmu,
ls=' ',
color='C1',
marker='o', markeredgecolor='k', markersize=5,
label='Observation', zorder=5)
ax.plot(zz, mu_poly, c='C3', alpha=0.8, lw=3, label='Best-fit')
ax.plot(z_true, mu_true, c='k', alpha=0.8, lw=3, ls='--', label='Truth')
ax.legend(loc=4, facecolor='white', framealpha=1)
ax.set_xlabel(r'z', fontsize=16)
ax.set_ylabel(r'$\mu$', fontsize=16)
ax.axis([0.001,1.8,35,48])
ax.tick_params(axis='both', which='major', labelsize=15)
plt.tight_layout()
plt.show()
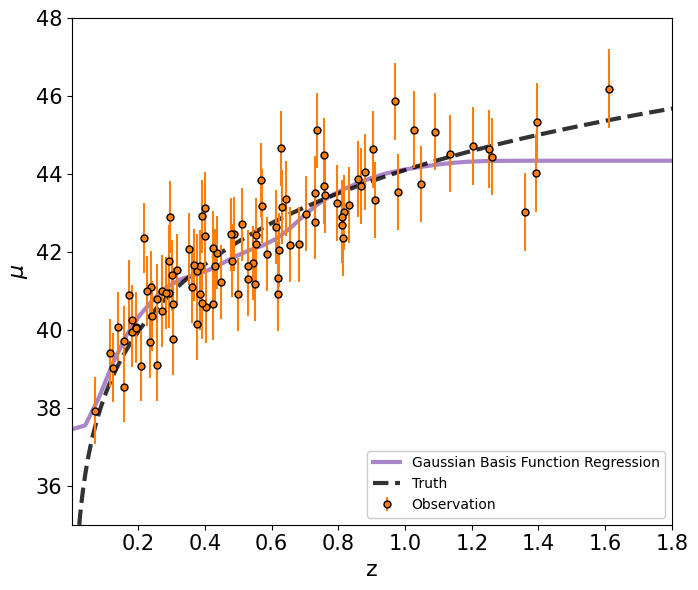
Basis Function Regression¶
In the linear regression framework, various categories of basis functions can be used instead of polynomials. These include Gaussian functions, trigonometric functions, Fourier basis functions, and spline functions. Below we show an example with Gaussian functions, represented as: \(g_p(x) = \mathcal{N}(\mu_1,\sigma_1)\). These basis functions transform the input variable xx into a higher-dimensional space, allowing for more complex relationships to be captured. Gaussian functions offer a flexible approach to modeling nonlinear relationships between variables within the linear regression framework.
[41]:
from astroML.linear_model import BasisFunctionRegression
[42]:
mu = np.linspace(0,1,6)[:,None]
sigma = 0.1
model = BasisFunctionRegression('gaussian', mu=mu, sigma=sigma)
model.fit(X_train[:,None], y_train, yerr_train)
zz = np.linspace(0,2)
mu_basis = model.predict(zz[:,None])
[43]:
fig, ax = plt.subplots(1,1,figsize=(7,6))
ax.errorbar(z_sample, mu_sample, yerr=dmu,
ls=' ',
color='C1',
marker='o', markeredgecolor='k', markersize=5,
label='Observation', zorder=5)
ax.plot(zz, mu_basis, c='C4', alpha=0.8, lw=3, label='Gaussian Basis Function Regression')
ax.plot(z_true, mu_true, c='k', alpha=0.8, lw=3, ls='--', label='Truth')
ax.legend(loc=4, facecolor='white', framealpha=1)
ax.set_xlabel(r'z', fontsize=16)
ax.set_ylabel(r'$\mu$', fontsize=16)
ax.axis([0.001,1.8,35,48])
ax.tick_params(axis='both', which='major', labelsize=15)
plt.tight_layout()
plt.show()
Learning about cosmology¶
Within our standard cosmological framework, we can approximate the luminosity distance of these supernovae using the following relation:
\(d_L\approx \frac{c}{H_0}z\left(1+\frac{1-q_0}{2}z\right)\) ,
where \(q_0\) is the deceleration paremeter. This parameter is related to the scale factor \(a(t)\) as
\(q_0=-\left(\frac{\ddot{a}a}{\dot{a}^2}\right)_{t=t_0}=-\left(\frac{\ddot{a}}{aH^2}\right)_{t=t_0}\) .
With this expression, the distance modulus becomes:
\(\mu(z) \approx 43.17 - 5\log_{10}\left(\frac{H_0}{70~\mathrm{km/s/Mpc}}\right)+5\log_{10}(z)+1.086(1-q_0)z\) .
For more description of the above expressions, see chapter 7 (or 6) of Introduction to cosmology, first (or second) edition, by Barbara Ryden.
[44]:
def dlum_linear(z, H0=70., q0=-0.55):
c = 3e8*units.m/units.s
if isinstance(H0,(int,float)):
H0 = H0*units.km/units.s/units.Mpc
d_hubble = (c/H0).to('Mpc')
dL = d_hubble*z*(1+(1-q0)/2*z)
return dL
def mu_linear(z, H0=70., q0=-0.55):
c = 3e8*units.m/units.s
if isinstance(H0,(int,float)):
H0 = H0*units.km/units.s/units.Mpc
H0_70 = 70*units.km/units.s/units.Mpc
mu = 43.17 - 5*np.log10((H0/H0_70).to('').value)+5*np.log10(z)+1.086*(1-q0)*z
return mu
[45]:
fig, ax = plt.subplots(1,1,figsize=(7,6))
ax.errorbar(z_sample, mu_sample, yerr=dmu,
ls=' ',
color='C1',
marker='o', markeredgecolor='k', markersize=5,
label='Observation', zorder=5)
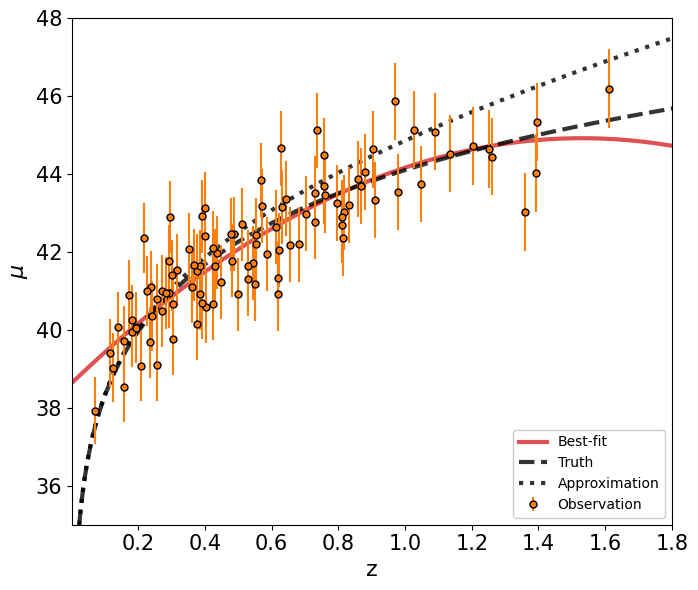
ax.plot(zz, mu_poly, c='C3', alpha=0.8, lw=3, label='Best-fit')
ax.plot(z_true, mu_true, c='k', alpha=0.8, lw=3, ls='--', label='Truth')
ax.plot(z_true, mu_linear(z_true), c='k', alpha=0.8, lw=3, ls=':', label='Approximation')
ax.legend(loc=4, facecolor='white', framealpha=1)
ax.set_xlabel(r'z', fontsize=16)
ax.set_ylabel(r'$\mu$', fontsize=16)
ax.axis([0.001,1.8,35,48])
ax.tick_params(axis='both', which='major', labelsize=15)
plt.tight_layout()
plt.show()
Bayesian parameter inference¶
This method is a powerful tool used to derived constraints on astrophysical and cosmological model by interpreting observations.
To find a model for a dataset with errorbar, we can define the loss function using the posterior distribution defined by the Bayes’ theorem as,
\(p(\theta|{x_i,y_i})\propto p({x_i,y_i}|\theta) p(\theta)\) ,
where \(p({x_i,y_i}|\theta)\) and \(p(\theta)\) are the data likelihood and the prior distribution, respectively.
Based on the central limit theorem, the each supernova data point can be assumed to be well defined by Gaussian distribution and, therefore, the likelihood can be given as,
\(p({x_i,y_i}|\theta) = \frac{1}{\sqrt{2\pi\sigma^2_i}} \mathrm{exp}\left(-\frac{[y_i-f(x_i|\theta)]^2}{2\sigma^2_i}\right)\) ,
where \(\sigma_i\) is the standard deviation of the \(i^\mathrm{th}\) data point. If we assume no prior knowledge, then \(p(\theta)=1\). Instead of likelihood (\(L\)), it is more convenient to work with log-likelihood:
\(\log(L) \propto - \sum^N_i \left(\frac{[y_i-f(x_i|\theta)]^2}{2\sigma^2_i}\right)\),
which should maximize for the best-fit.
Simple example of Bayesian inference¶
We consider a simple example of observation points scattered about a straight line given as \(y(x,m,b) = mx+b\). \(x\) is the vector containing the points where observations were taken.
[46]:
true_m = 2
true_b = 1
x_obs, y_obs, y_err = AstronomyCalc.line_data(true_m=true_m, true_b=true_b, sigma=2, error_sigma=0.5).T
[47]:
def model(param):
m, b = param
return m*x_obs+b
[48]:
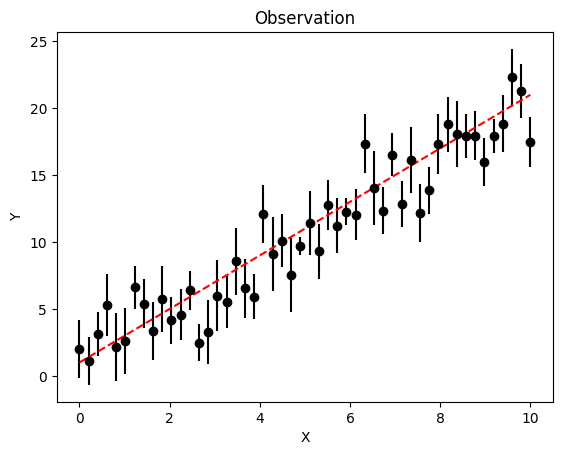
true_param = [true_m,true_b]
plt.title('Observation')
plt.errorbar(x_obs, y_obs, yerr=y_err, color='k', ls=' ', marker='o')
plt.plot(x_obs, model(true_param), color='r', ls='--')
plt.xlabel('X')
plt.ylabel('Y')
plt.show()
As mentioned above, we assume a Gaussian likelihood for this analysis. We also define a flat prior for the parameters of the model. We restrict the explored parameter space to remain within minimum values vector mins and maximum values vector maxs.
[49]:
def log_likelihood(param):
y_mod = model(param)
# y_err = 0.5*y_obs
logL = -np.sum((y_obs-y_mod)**2/2/y_err**2)
return logL
mins = np.array([-2,-3])
maxs = np.array([6,5])
def log_prior(param):
m, b = param
if mins[0]<=m<=maxs[0] and mins[1]<=b<=maxs[1]:
return 0
else:
return -np.inf
def log_probability(param):
lp = log_prior(param)
if np.isfinite(lp):
return lp+log_likelihood(param)
return -np.inf
[50]:
print(f'logL({true_param}) =', log_probability(true_param))
param = [0,1]
print(f'logL({param}) =', log_probability(param))
param = [10,1]
print(f'logL({param}) =', log_probability(param))
logL([2, 1]) = -26.545129387851276
logL([0, 1]) = -953.4748879076326
logL([10, 1]) = -inf
Importance Sampling¶
Importance Sampling is a Monte Carlo method used to evaluate properties of an unknown distribution by using samples generated from a different, known distribution called the proposal distribution. This technique allows us to approximate the target distribution, which in many cases is the posterior distribution of interest, using samples drawn from the proposal distribution.
Importance Sampling Algorithm Steps:
We provide the steps along with application to our example case using a implementation of this algorithm in AstronomyCalc.
Define the Target Distribution:
Let ( p(x) ) be the target distribution you wish to sample from. This is often the posterior distribution in a Bayesian context.
[51]:
def target_distribution(param):
if np.array(param).ndim==1: return np.exp(log_probability(param))
else: return np.array([np.exp(log_probability(par)) for par in param])
Choose a Proposal Distribution:
Select a proposal distribution \(q(x)\) from which it is easier to draw samples. The proposal distribution should be chosen so that it covers the regions where \(p(x)\) has significant mass.
A commonly used proposal distribution is a multivariate Gaussian, which used in this AstronomyCalc implementation.
[52]:
# Set up the proposal distribution mean and covariance of the Gaussian proposal distribution.
proposal_mean = [2.5, 1.5]
proposal_cov = [[2.0, 1.5], [1.5, 2.0]]
[53]:
# Initialize the Importance Sampling with default Gaussian proposal
is_sampler = AstronomyCalc.ImportanceSampling(target_distribution, proposal_mean=proposal_mean, proposal_cov=proposal_cov)
Generate Samples:
Draw \(N\) independent samples ( \(x_1, x_2, \ldots, x_N\) ) from the proposal distribution \(q(x)\).
Compute Importance Weights:
For each sample \(x_i\), compute the importance weight:
\(w_i = \frac{p(x_i)}{q(x_i)}\).
These weights represent how much each sample should be “counted” when approximating the target distribution.
Normalize the importance weights to sum to 1:
\(\tilde{w}_i = \frac{w_i}{\sum_{j=1}^N w_j}\) .
[54]:
# Draw samples and compute expectation
samples, weights = is_sampler.sample(n_samples=1000)
Post-Processing:
From sampler, we got the samples (\(x_1\), \(x_2\), \(\ldots\), \(x_N\)) and corresponding weights (\(w_1\), \(w_2\), \(\ldots\), \(w_N\)) that we can be used to approximate the posterior distribution.
[55]:
labels = ['$m$', '$b$']
[56]:
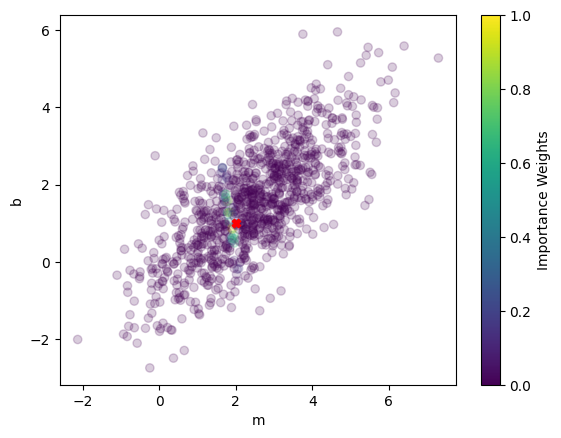
plt.scatter(samples[:, 0], samples[:, 1], c=weights, cmap='viridis', alpha=0.2)
plt.scatter(true_m, true_b, marker='X', color='red')
plt.xlabel('m')
plt.ylabel('b')
plt.colorbar(label='Importance Weights')
plt.show()
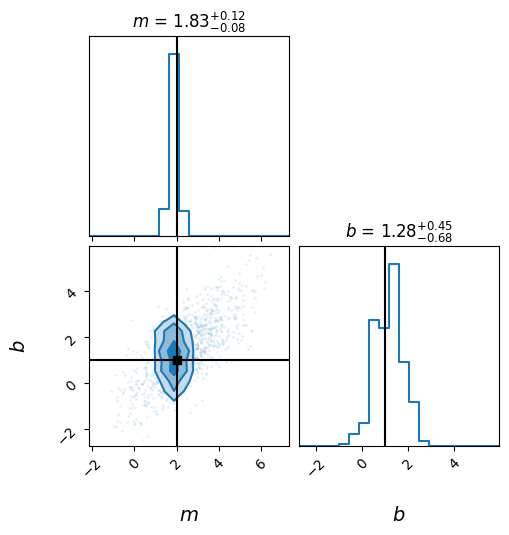
[57]:
AstronomyCalc.plot_posterior_corner(samples, labels, truths=true_param, weights=weights)
(1000, 2)
Notes on Importance Sampling
While Importance Sampling can effectively approximate the posterior distribution in simpler cases, it becomes inefficient for large and high-dimensional parameter spaces. To address these limitations, several improvements have been developed, such as Sequential Monte Carlo.
In this tutorial, we will also explore another method that converges more effectively to the target distribution.
Metropolis–Hastings Algorithm¶
The Metropolis–Hastings algorithm is a widely used Markov chain Monte Carlo (MCMC) method for generating a sequence of random samples from a probability distribution, especially when direct sampling is challenging or impossible. This method is particularly valuable in Bayesian statistics, where we often need to sample from complex posterior distributions that cannot be sampled directly.
The key idea behind the Metropolis–Hastings algorithm is to construct a Markov chain whose equilibrium distribution is the target distribution. By running the chain for a sufficient number of iterations, the samples generated will approximate the desired distribution, allowing us to estimate properties such as means, variances, and credible intervals.
Metropolis-Hastings Algorithm Steps:
We provide the steps along with application to our example case using a implementation of this algorithm in AstronomyCalc.
Initialize the Chain:
Choose an initial point (\(x_0\)) from the state space.
Set the initial step to (\(n = 0\)).
[58]:
nwalkers = 8 #Independent walkers that will sample the distribution.
ndim = 2 #Dimension of the parameter space
n_samples = 1000 #Total number of samples we want to obtain from each walker
# Setup a sampler
mh_sampler = AstronomyCalc.MetropolisHastings(nwalkers=nwalkers, ndim=ndim, log_probability=log_probability,
proposal_cov=np.eye(ndim), n_jobs=2)
[59]:
# We randomly initialise the walkers are different locations
# inside the mininum and maximun ranges of the parameter space
initial_value = np.random.uniform(size=(nwalkers, ndim))*(maxs-mins)+mins
mh_sampler.initialise(initial_value)
Proposal Step:
Propose a new candidate point (\(x^*\)) from a proposal distribution \(q(x^* | x_n)\), which suggests a new state based on the current state (\(x_n\)).
A commonly used proposal distribution is a multivariate Gaussian. We denote a new sample drawn from this distribution as: \(x^* \mid x_n \sim \mathcal{N}(x_n, \sigma^2)\), where \(\sigma^2\) is the covariance matrix that controls the extent to which we explore from any given position in the parameter space. If \(\sigma^2\) is too small, the chain will exhibit slow mixing. This occurs because the acceptance rate might be high, but the chain’s successive samples will move very slowly through the space, leading to slow convergence to the target distribution \(p(x)\). Conversely, if \(\sigma^2\) is too large, the acceptance rate will be very low. This happens because the proposed samples are likely to fall in regions with much lower probability density, resulting in a very small acceptance probability \(\alpha\), and hence, slow convergence of the chain.
For a Gaussian proposal, the proposal distribution is symmetric, meaning \(q(x_n \mid x^*) = q(x^* \mid x_n)\). Therefore, the acceptance probability simplifies to: \(\alpha = \min\left(1, \frac{p(x^*)}{p(x_n)}\right)\).
[60]:
#We assume the covariance of the Gaussian proposal is a diagonal matrix.
proposal_cov = np.eye(ndim)
print('Drawing new samples from the initial value.')
new_samples = []
for i in range(nwalkers):
new_sample, q21, q12 = mh_sampler.draw_from_proposal(initial_value[i], proposal_cov)
print(f'Walker Number {i}: {initial_value[i]} ->', new_sample)
new_samples.append(new_sample)
new_samples = np.array(new_samples)
Drawing new samples from the initial value.
Walker Number 0: [-0.90719277 2.21311808] -> [-1.13579269 1.21876871]
Walker Number 1: [ 3.90877967 -0.47498125] -> [ 1.34644601 -0.66600901]
Walker Number 2: [3.15866083 0.16104726] -> [5.57127625 0.94565155]
Walker Number 3: [ 3.70565507 -1.4062778 ] -> [ 3.68639469 -1.66916863]
Walker Number 4: [ 5.12172002 -0.70072323] -> [ 5.14418591 -0.15360411]
Walker Number 5: [ 0.9422879 -2.53526438] -> [-0.23852491 -1.42094269]
Walker Number 6: [-1.1079023 1.12689522] -> [-0.39252099 1.84508095]
Walker Number 7: [0.14074141 3.68384181] -> [0.57921715 3.70345846]
[61]:
plt.scatter(true_param[0], true_param[1], color='k', marker='X')
for i in range(nwalkers):
plt.scatter(initial_value[i,0], initial_value[i,1], color=f'C{i}', label='$x_n$' if i==0 else None)
plt.annotate('', xy=(new_samples[i,0], new_samples[i,1]), xytext=(initial_value[i,0], initial_value[i,1]),
arrowprops=dict(facecolor='red', edgecolor='grey', arrowstyle='->', lw=1))
plt.scatter(new_samples[i,0], new_samples[i,1], color=f'C{i}', label='$x_{n+1}$' if i==0 else None)
plt.axis([mins[0],maxs[0],mins[1],maxs[1]])
plt.legend()
plt.xlabel('$m$')
plt.ylabel('$b$')
plt.show()
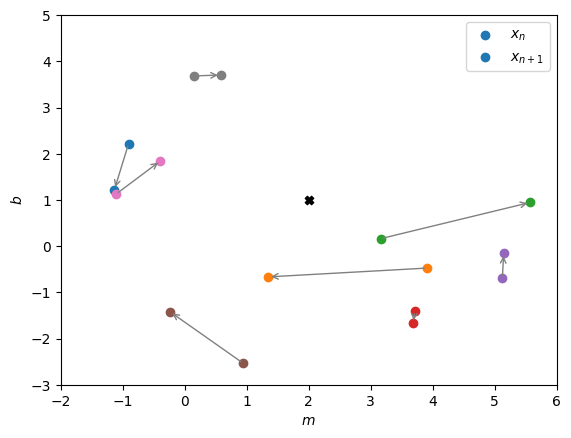
Acceptance Probability:
Calculate the acceptance probability ( \(\alpha\) ) for moving from the current state (\(x_n\)) to the proposed state (\(x^*\)):
\(\alpha = \min\left(1, \frac{p(x^*) \cdot q(x_n | x^*)}{p(x_n) \cdot q(x^* | x_n)}\right)\)
Here, \(p(x)\) is the target distribution we want to sample from, and \(q(x'|x)\) is the proposal distribution.
[62]:
p_acc = np.array([mh_sampler.acceptance_probability(initial_value[i], new_samples[i], q21, q12) for i in range(nwalkers)])
Accept or Reject the Proposal:
Generate a random number \(u\) from a uniform distribution \(U(0, 1)\).
If \(u \leq \alpha\), accept the proposed state and set \(x_{n+1} = x^*\).
If \(u > \alpha\), reject the proposed state and set \(x_{n+1} = x_n\).
[63]:
u_acc = np.array([np.random.uniform(0,1) for i in range(nwalkers)])
print('Comparing u and a:')
accept_array = []
for i in range(nwalkers):
accept = (u_acc[i]<=p_acc[i])
if accept: print(f'Walker Number {i}: {u_acc[i]:.5f} <= {p_acc[i]:.5f}')
else: print(f'Walker Number {i}: {u_acc[i]:.5f} > {p_acc[i]:.5f}')
accept_array.append(accept)
Comparing u and a:
Walker Number 0: 0.12555 > 0.00000
Walker Number 1: 0.01695 <= 1.00000
Walker Number 2: 0.77016 > 0.00000
Walker Number 3: 0.80716 <= 1.00000
Walker Number 4: 0.12021 > 0.00000
Walker Number 5: 0.26558 > 0.00000
Walker Number 6: 0.01755 <= 1.00000
Walker Number 7: 0.29331 <= 1.00000
[64]:
plt.scatter(true_param[0], true_param[1], color='k', marker='X')
for i in range(nwalkers):
plt.scatter(initial_value[i,0], initial_value[i,1], color=f'C{i}', label='$x_n$' if i==0 else None)
plt.annotate('', xy=(new_samples[i,0], new_samples[i,1]), xytext=(initial_value[i,0], initial_value[i,1]),
arrowprops=dict(facecolor='red', edgecolor='grey', arrowstyle='->', lw=1))
plt.scatter(new_samples[i,0], new_samples[i,1], color=f'C{i}', label='$x_{n+1}$' if i==0 else None)
plt.scatter(new_samples[accept_array,0], new_samples[accept_array,1],
edgecolor='green', facecolor='none', s=100, linewidth=1.5, label='Accepted')
plt.axis([mins[0],maxs[0],mins[1],maxs[1]])
plt.legend()
plt.xlabel('$m$')
plt.ylabel('$b$')
plt.show()
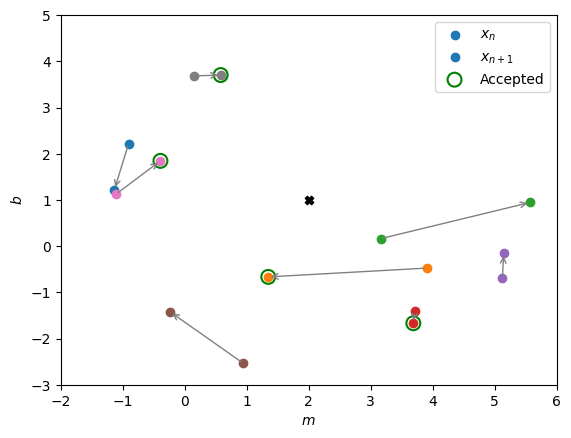
Iterate:
Repeat steps 2 to 4 for a large number of iterations to allow the chain to converge to the target distribution.
[65]:
samples = mh_sampler.run_sampler(n_samples=n_samples, initial_value=initial_value)
print("Samples shape:", samples.shape)
100%|█████████████████████████████████████████████████████████████████████| 1000/1000 [00:01<00:00, 788.28it/s]
Samples shape: (8, 1000, 2)
Post-Processing:
After running the chain, the samples (\(x_1\), \(x_2\), \(\ldots\), \(x_N\)) can be used to approximate the target distribution. Typically, the initial portion of the chain (referred to as the “burn-in” period) is discarded to reduce the impact of the initial state.
[66]:
labels = ['$m$', '$b$']
fig, axs = plt.subplots(ndim, 1, figsize=(5,ndim*3))
fig.suptitle('Trace plot')
for i in range(ndim):
axs[i].set_ylabel(labels[i], fontsize=16)
axs[i].set_xlabel('step number', fontsize=16)
for j in range(nwalkers):
axs[i].plot(samples[j,:,i], c=f'C{j}')
plt.tight_layout()
plt.show()
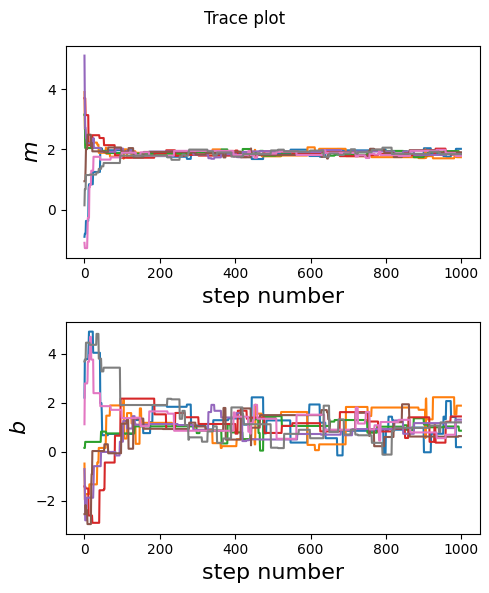
[67]:
# We flatten the samples received from all the walkers after removing burn-in
flat_samples = mh_sampler.get_flat_samples(burn_in=10)
print('Flat samples shape:', flat_samples.shape)
Flat samples shape: (7920, 2)
[68]:
AstronomyCalc.plot_posterior_corner(flat_samples, labels, truths=true_param)
(7920, 2)
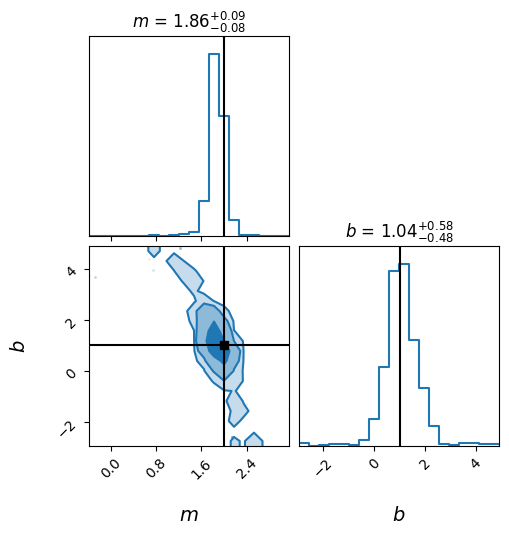
Notes on Metropolis-Hasting Algorithm Here we used a naive implementation of the algorithm. However, there exists sophisticated packages that employ more robust improvements to better explore the parameter space. Few examples of such open-source packages are emcee and pyMC.
Inferring cosmological parameters from supernova data¶
We generate distance modulus data \(\mu(z)\) given as,
\(\mu(z) = 5\log_{10}\left(\frac{d_L(z)}{1~\mathrm{Mpc}}\right)+25\) ,
where \(d_L\) is the luminosity distance estimated by observing supernova. This distance is related to the comoving distance \(d_c(z)\) as,
\(d_L(z) = (1+z) d_c(z) = (1+z)\frac{c}{100 h_0}\int\frac{dz}{\left[\Omega_m(1+z)^3+\Omega_\Lambda\right]^{1/2}}\) .
For a flat universe, \(\Omega_\Lambda = 1-\Omega_m\). Therefore, in this model, we will infer two cosmological parameters \((h_0, \Omega_m)\).
[69]:
def model(param, zz):
h0, Om0 = param
param = AstronomyCalc.param()
param.cosmo.Om = Om0
param.cosmo.Or = 0.0
param.cosmo.Ok = 0.0
param.cosmo.Ode = 1-Om0 #Flat Universe
param.cosmo.h = h0
return AstronomyCalc.distance_modulus(param,zz)
param_true = [0.70,0.30]
z_true = np.linspace(0.01, 2, 1000)
mu_true = model(param_true, z_true)
dmu_0=0.1
dmu_1=0.001
z_sample, mu_sample, dmu = AstronomyCalc.generate_distance_modulus(n_samples=100, z0=0.3, dmu_0=dmu_0, dmu_1=dmu_1)
dmu_sample = dmu_0+dmu_1*mu_sample
print(z_sample.shape, mu_sample.shape, dmu.shape)
(100,) (100,) (100,)
[70]:
fig, ax = plt.subplots(1,1,figsize=(7,6))
ax.errorbar(z_sample, mu_sample, yerr=dmu,
ls=' ',
color='C1',
marker='o', markeredgecolor='k', markersize=5,
label='Observation', zorder=5)
ax.plot(z_true, mu_true, c='k', alpha=0.8, lw=3, ls='--', label='Truth')
ax.legend(loc=4, facecolor='white', framealpha=1)
ax.set_xlabel(r'z', fontsize=16)
ax.set_ylabel(r'$\mu$', fontsize=16)
ax.axis([0.001,1.8,35,48])
ax.tick_params(axis='both', which='major', labelsize=15)
plt.tight_layout()
plt.show()
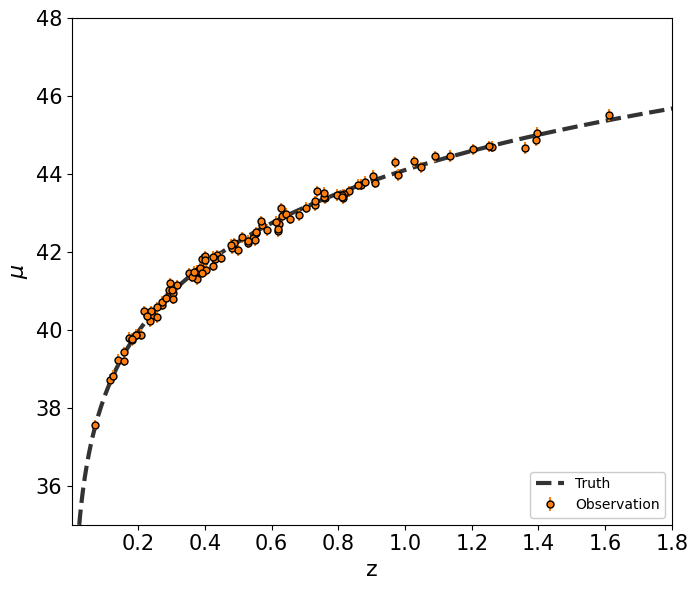
Now we will apply the MCMC method studied above to this cosmological data and infer the cosmological parameters.
[71]:
def log_likelihood(param):
zz_obs = z_sample
mu_obs = mu_sample
covinv = np.eye(len(mu_sample))*(1/dmu_sample**2)
mu_mod = model(param,zz_obs)
delta = (mu_obs-mu_mod)
logL = -0.5*np.dot(delta.T, np.dot(covinv, delta))
return logL
mins = np.array([0.50,0.01])
maxs = np.array([0.90,0.50])
def log_prior(param):
H0, Om0 = param
lp = 0
for i in range(len(mins)):
if mins[i]<=param[i]<=maxs[i]:
lp += 0
else:
return -np.inf
return lp
def log_probability(param):
lp = log_prior(param)
if np.isfinite(lp):
return lp+log_likelihood(param)
return -np.inf
[72]:
param_true = [0.70,0.30]
print(f'logL({param_true}) =', log_probability(param_true))
param = [0.10,0.31]
print(f'logL({param}) =', log_probability(param))
param = [0.60,0.31]
print(f'logL({param}) =', log_probability(param))
logL([0.7, 0.3]) = -40.61810691066014
logL([0.1, 0.31]) = -inf
logL([0.6, 0.31]) = -316.7496238662658
[73]:
nwalkers = 16
ndim = len(mins)
n_samples = 3000
initial_value = np.random.uniform(size=(nwalkers, ndim))*(maxs-mins)+mins
# Setup a sampler
mh_sampler = AstronomyCalc.MetropolisHastings(nwalkers=nwalkers, ndim=ndim, log_probability=log_probability,
proposal_cov=np.eye(ndim)*0.01, n_jobs=4)
samples = mh_sampler.run_sampler(n_samples=n_samples, initial_value=initial_value)
print("Samples shape:", samples.shape)
100%|██████████████████████████████████████████████████████████████████████| 3000/3000 [04:24<00:00, 11.35it/s]
Samples shape: (16, 3000, 2)
[74]:
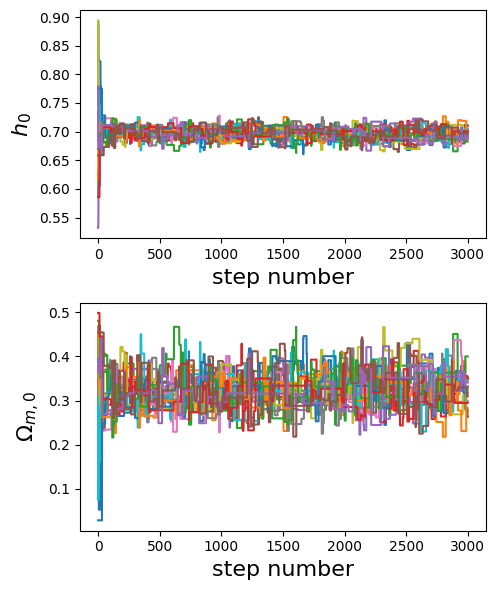
labels = ['$h_0$', '$\Omega_{m,0}$']
fig, axs = plt.subplots(ndim, 1, figsize=(5,ndim*3))
for i in range(ndim):
axs[i].set_ylabel(labels[i], fontsize=16)
axs[i].set_xlabel('step number', fontsize=16)
for j in range(nwalkers):
axs[i].plot(samples[j,:,i], c=f'C{j}')
plt.tight_layout()
plt.show()
[75]:
flat_samples = mh_sampler.get_flat_samples(burn_in=50)
print('Flat samples shape:', flat_samples.shape)
AstronomyCalc.plot_posterior_corner(flat_samples, labels, truths=param_true)
Flat samples shape: (47200, 2)
(47200, 2)
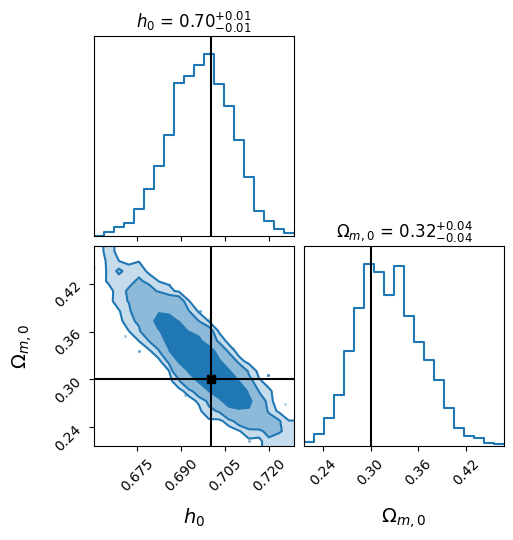
Though we showed the analysis with only two cosmological parameters, the framework is generic enough to test more complex theories, such as dynamical dark energy models.